
 The forensic data analytics (FDA) landscape is rapidly evolving, characterized by an increasing array of tools and technologies, accelerating regulatory expectations, and growing data volumes.
The forensic data analytics (FDA) landscape is rapidly evolving, characterized by an increasing array of tools and technologies, accelerating regulatory expectations, and growing data volumes.
The tabular reports that were standard throughout the 2000s may now seem insufficient to leaders in fighting fraud. Powerful technologies such as artificial intelligence, interactive data visualization, cognitive computing, and the "Internet of Things" are facilitating new ways of managing fraud risk within organizations, and at a scale and degree of precision never before possible.
This changing environment presents opportunities for risk management professionals and finance executives to increase the effectiveness of their anti-fraud programs by employing FDA tools and technologies. However, when unmanaged or not properly deployed, an organization's analytics journey can be marked by frustrated users and unachieved expectations.
Recommended For You
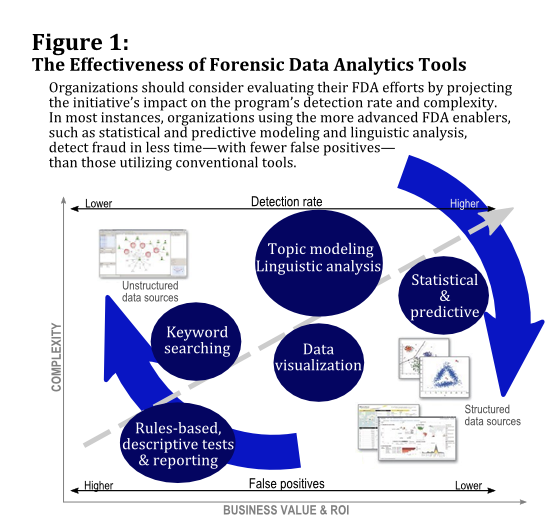
FDA technologies are continuously advancing, and most of them involve some combination of the following techniques:
Rules-based Tests and Risk Scoring
Rules-based tests are one of the most-utilized FDA techniques. Analytics applications run transactions through a set of predefined conditions and policies; transactions that fail the tests are flagged for further attention in the fraud-prevention workflow. The popular use cases for rules-based tests include bribery and corruption, money laundering, travel and entertainment (T&E) expense fraud, and abuse in inventory and procurement management, where the fraud schemes are diverse but fairly well understood.
A company can enhance these tests using risk scoring. For example, let's consider two payment transactions:
Payment 1 — Amount: $250 • Date: Saturday, January 1 Country: Nigeria • Description: Customs facilitation payment
Payment 2 — Amount: $324 • Date: Monday, January 3 Country: United Kingdom • Description: Hotel in London for meeting with government
Suppose the company runs all its payments through three anti-fraud analytics tests that identify transactions which: (a) occur on a weekend, when normal accounting operations are suspended; (b) are for a round dollar amount; or (c) include the keywords customs, facilitation, government, and/or expedite. Rather than alerting the risk management team whenever a payment fails one of these three tests, the company may develop a crude, baseline risk score using the following guidelines:
- Scaling: Since tests (a) and (b) each have two possible values, risk managers assign a "Yes" answer a value of 1, while assigning "No" a value of 0. For test (c), they count each keyword hit as one point.
- Weighting: Next, risk managers assign each test a weighting value of 1 through 5, depending on the perceived risks. Suppose that in this example, the organization is very interested in tests (a) and (c) but less interested in test (b). Risk managers assign a weighting value of 4 to tests (a) and (c) and a weighting value of 2 to test (b).
Thus, the risk scores for the two transactions would be:
Payment 1: (1 x 4) + (1 x 2) + (2 x 4) = 4 + 2 + 8 = 14
Payment 2: (0 x 4) + (0 x 2) + (1 x 4) = 0 + 0 + 4 = 4
Any one alert generated through rules-based tests may not be indicative of a significant risk. However, bringing multiple analytics results together into a combined risk score can help the organization prioritize risk alerts and establish appropriate escalation procedures in order to achieve both effectiveness and efficiency.
Keyword Searching
In data sets that contain unstructured data, such as text fields in payments or purchase orders, keyword searching can provide an efficient way to hone in on suspicious or high-risk language. For example, risk-related keywords found in the payments data can be applied to other electronic communications to look for further clues. This technique is frequently used in response to a specific incident; however, it can also be used in ongoing monitoring to detect new fraud patterns by culling known, relevant keywords and applying them in real-time searches.
Many generic, risk-related keyword lists are obtainable in the public domain. Organizations should complement those generic lists by developing custom lexicons based on past incidents from inside the organization or peer companies, and continuously refine them over time. The keywords list should be treated as the signature files of an anti-virus software that needs to be updated regularly to be effective.
 An increasing number of organizations are leveraging more advanced keyword-searching techniques within their anti-fraud programs. One increasingly popular technique is "fuzzy matching." It uses word-based queries to find matching phrases or sentences from a database when exact matching cannot be found. For example, this would mean that searching for facilitation payment would return hits on phrases such as facilitate paying fees.
An increasing number of organizations are leveraging more advanced keyword-searching techniques within their anti-fraud programs. One increasingly popular technique is "fuzzy matching." It uses word-based queries to find matching phrases or sentences from a database when exact matching cannot be found. For example, this would mean that searching for facilitation payment would return hits on phrases such as facilitate paying fees.
Another popular technique is "text-link analysis," which applies pattern-matching technology to the concept identification in text mining, in order to uncover relationships between concepts based on known patterns. The findings can help detect hidden intent of a potential fraud. For example, information about a certain transaction may not be interesting to the current cause; however, linking all other payments and fees associated with the transaction may be of interest, because it may reveal hidden fraudulent intent and give insight into potential fraud.
Data Visualization
Modern accounts payable, accounts receivable, and related systems have very large data sets. Driving insight and action from data sets of this size requires powerful analysis and data visualization tools. Interactive dashboards can be helpful in providing the context underlying a data analysis and in telling the story behind the data. They also translate textual data into incident maps and charts for a full view of connections and hidden links.
In order to make data visualization tools useful for risk managers, organizations need to develop a strategy to guide their creation and refinement. A failure to take into consideration certain important questions can lead to increased costs as a result of disjointed processes, as well as misinterpretation of the implied risks. This could result in real risks being ignored.
Some key considerations are:
- What case management tools should be integrated with the data visualization tool to provide easy end-user access?
- What elements of our anti-fraud workflows can benefit from visualization?
- How should we customize and control access to the information based on user profile?
- What risk indicators should we include? What data sources are required to construct each risk indicator?
- How should risk scores be visualized to show risks' severity levels, critical assets that are impacted, and other risk areas that require immediate attention?
- And what is the next level of detail for each risk indicator that should be made available if needed?
Topic Modeling and Linguistic Analysis
Anti-fraud efforts can be even more successful when they delve into patterns of human behavior that reveal suspicious motives. Beyond keyword searching, topic modeling seeks to cluster, quantify, and group the key noun or noun phrases in the data, enabling the investigative team to quickly gain an understanding of what information may have been compromised or the corrupt intent of certain business activities. Linguistic analysis techniques use the results of text analytics to identify the emotive tone of a communication—identifying angry, frustrated, secretive, harassing, or confused communications, among other sentiments.
Statistical and Predictive Modeling
Leading anti-fraud programs have been adding predictive and statistical modeling to their analytics mix. Statistical and predictive modeling leverages historical data and machine learning technologies to detect and project future or otherwise unknown events, giving organizations the ability to proactively manage fraud risk. Risk models that are built based on statistical and predictive models can be used to project the impact of high-risk potential fraud events and also to flag suspect payments or patterns. The incorporation of statistical models into this approach helps pinpoint abnormal behaviors or activities that warrant additional review, thus limiting the number of false positives and increasing the efficiency of the review process.
What the Risk Management Community Thinks About FDA
As part of EY's biennial "Global Forensic Data Analytics Survey," we conducted research and interviews with more than 600 executives. These executives' descriptions of how their companies are using forensic data analytics suggest several interesting trends:
More is better. Organizations analyzing large volumes and wide varieties of data are reporting better results in fraud detection.
"Big data" platforms have matured to a point where combining data from a wide variety of sources, unstructured and structured, is now possible, and companies are finding great value in doing so. Data ingestion tools enable companies to extract, transform, and ingest large amounts of disparate data, from varying data sources, and normalize the data into a usable format for immediate analysis or for storage in a database for future use when they need to revisit it during an investigation. Meanwhile, advances in distributed processing give organizations the ability to handle large data computation by dividing and spreading the task across multiple processors that run in parallel.
Blend, fuse and unify. Successful organizations are moving toward consolidated dashboards to gain a unified picture across data sets. For instance, organizations are countering the insider threat—defined as current or ex-employees who intentionally utilize authorized access to an organization's digital assets to compromise their confidentiality, integrity, or availability—by executing a series of tests and utilizing link analysis to amalgamate the results. Any single alert or trigger identified through conventional rules-based tests may not be indicative of a significant risk. However, bringing multiple analytics results together can rapidly drive down the risks of encountering false positives.
Commit to spending on forensic data analytics. The majority of respondents in our 2016 survey who committed at least one-third of their total anti-fraud program budget to forensic data analytics are seeing positive results. Companies should align FDA investment with their evolving risk profiles. For instance, corruption and insider threats have high risk levels in many emerging markets that companies may be contemplating entering. Existing, high-performing anti-fraud analytics programs may not be nearly as effective in a newly acquired international operation due to new and specific risks for that particular geography. Thus, additional tests will need to be developed.
FDA tools and technologies have advanced significantly over the past decade. Organizations concerned about fraud should consider how they can best harness the power of forensic data analytics, and should gain a clear understanding of potential pitfalls, such as low business participation, insufficient resources to regularly assess and fine-tune the performance of the analytical models, and the tendency to rush enterprisewide deployment without a clearly defined road map.
In addition, companies need to recognize the human elements required for a successful FDA implementation, which often include the business and technical skills required to define tests and analyze and interpret results, as well as the domain proficiency to apply FDA tools appropriately.
See also:
- Who's Legally Liable for a Risk Management Failure?
- ERM Boosts Compliance Success
- Are We Getting Risk Management Right?
 Todd Marlin is a principal and the Americas Forensic Data Analytics and Data Sciences leader in the Fraud Investigation & Dispute Services division of Ernst & Young LLP. His main focus areas are forensic data analytics, cybersecurity, computer forensics, fraud detection, and electronic discovery. Marlin is a trusted adviser on complex issues surrounding data, security, and legal and compliance risks. He has appeared on behalf of clients in front of the NYSE and SEC, served as an expert, and has been appointed in federal court as a Special Master relating to electronic discovery disputes.
Todd Marlin is a principal and the Americas Forensic Data Analytics and Data Sciences leader in the Fraud Investigation & Dispute Services division of Ernst & Young LLP. His main focus areas are forensic data analytics, cybersecurity, computer forensics, fraud detection, and electronic discovery. Marlin is a trusted adviser on complex issues surrounding data, security, and legal and compliance risks. He has appeared on behalf of clients in front of the NYSE and SEC, served as an expert, and has been appointed in federal court as a Special Master relating to electronic discovery disputes.
The opinions expressed herein are those of the author and do not necessarily reflect the opinions of EY or its member firms.
© Touchpoint Markets, All Rights Reserved. Request academic re-use from www.copyright.com. All other uses, submit a request to [email protected]. For more inforrmation visit Asset & Logo Licensing.

